说说久经考验的机器学习经典模型。
LR models
逻辑回归模型简单,解释性好,使用极大似然估计对训练数据进行建模。 它由两部分构成: 线性回归 + 逻辑函数
采用梯度下降法对LR进行学习训练,LR的梯度下降法迭代公式非常简洁。 LR适合离散特征,不适合特征空间大的情况。
GBM models
xgbost
catboost
RandomForest
FM models
对categorical类型进行独热编码变成数值特征(1变多)之后,特征会非常稀疏(非零值少),特征维度空间也变大。因此FM的思路是构建新的交叉特征。
FM的表达式是在线性表达式后面加入了新的交叉项特征及对应的权值。 相比于LR, FM引入了二阶特征, 增强了模型的学习能力和表达能力。
https://www.cnblogs.com/wkang/p/9588360.html
FFM
Field-aware Factorization Machine
Deep-learning based CTR models
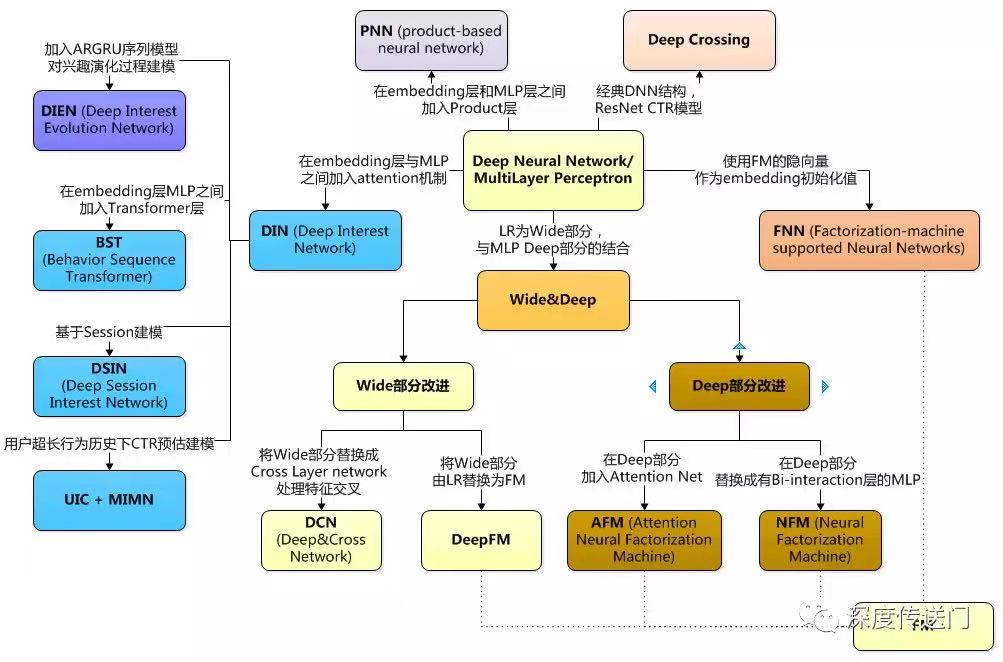
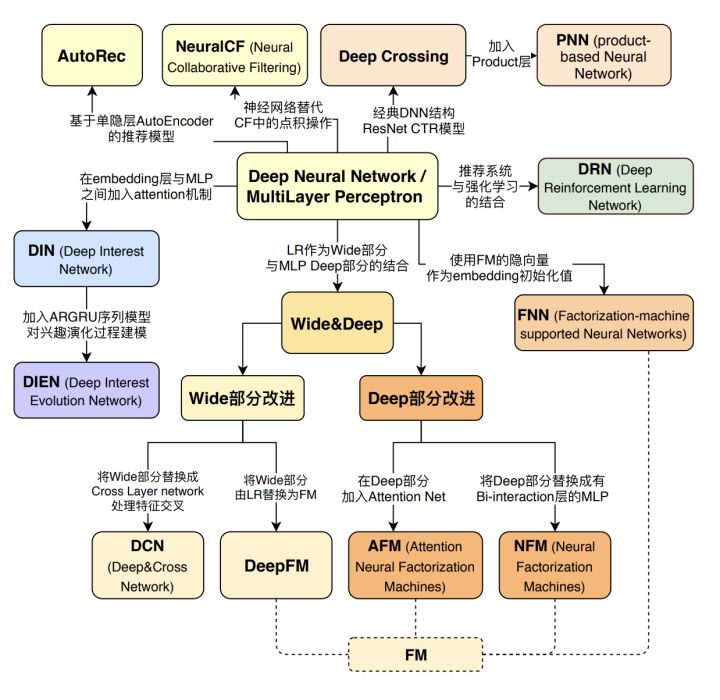
搜推广场景的特点:
- Sparse model
- Discrete features
Wide and Deep learning WDL模型
可以看做是 LR + DNN
- wide model (logistic regression with sparse features and transformations) wide的部分具有较强的记忆能力,协同过滤、逻辑回归等简单模型的记忆能力较强。
- deep model (feed-forward neural network with an embedding layer and several hidden layers) deep的部分具有较强的泛化能力,
DeepFM 模型
将LR替换为FM。 可以看做是 FM + DNN
Deep&Cross DCN 模型
它和Wide&Deep的差异就是用cross网络替代wide的部分。
Cross Layer
DIN & DIEN
在embedding层和MLP层之间加入 attention 机制
FFN
feed forward层。他本质上就是一个两层的MLP。 在Bert中,FFN的具体结构是 matmul -> bias_gelu -> matmul
MOE
MoE(Mixture of Experts) 模型架构在很多年都有了,后来LLM中也使用。 https://github.com/chenzomi12/AIInfra/tree/main/06AlgoData/02MoE
- 稀疏 MoE 层: MoE 层代替传统 Transformer 中 FFN 层。
- 门控网络或路由:用于决定哪些 token 发送到哪个专家。
import tensorflow as tf
class MoE(tf.keras.Model):
def __init__(self, num_experts, input_shape, output_dim):
super(MoE, self).__init__()
self.gate = tf.keras.Sequential([
tf.keras.layers.Conv2D(32, 3, activation='relu', input_shape=input_shape),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(num_experts, activation='softmax')
])
self.experts = [tf.keras.Sequential([
tf.keras.layers.Conv2D(64, 3, activation='relu', input_shape=input_shape),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(output_dim)
]) for _ in range(num_experts)]
def call(self, inputs):
gate_outputs = self.gate(inputs) # 计算每个专家的权重
# 选择权重最高的专家
selected_expert_indices = tf.argmax(gate_outputs, axis=-1)
# 根据选择的专家索引获取专家输出
expert_outputs = tf.stack([self.experts[i](inputs) for i in selected_expert_indices], axis=0)
# 由于每个样本只选择一个专家处理,所以这里不需要加权求和
final_output = tf.gather(expert_outputs, tf.range(tf.shape(inputs)[0]), axis=0)
return final_output
# 创建MoE模型实例,假设输入是28x28的灰度图像,输出是一个标量
model = MoE(num_experts=2, input_shape=(28, 28, 1), output_dim=1)
Deep-learning based NLP models
Batch Negative
通过在批量样本中引入负样本,更好地优化推荐系统模型。具体来说,Batch Negative 使用了负采样的方法,在每个训练批次中引入了一些负样本。这些负样本是从用户未观察到的项目中随机选择的。
Deep-learning based CV models
LeNet-5网络,AlexNet,VGG网络,GoogLeNet,残差网络
GAN models
- 基于显式概率密度函数的生成模型
- 套路:建立所需拟合的数据分布的概率密度函数,不断训练。
- 若目标优化函数可解,直接用优化算法求解最优参数。 代表:FVBN。
- 若目标优化函数不可解,用最近方法求解最优参数。 代表:变分近似算法(VAE)、马尔克夫蒙特卡洛算法(玻尔兹曼机)。
- 基于隐式概率密度函数的生成模型
- 套路:直接采样的方式训练模型参数,不提前对真实数据的分布建立模型。 代表:GAN
GAN由两个子模型组成:
- 生成器G
- G的输入是随机噪声向量
- G的输出是与真实数据维度相同的数据
- G的目标是生成尽可能接近真实数据的伪造数据
- 判别器D
- D的输入是真实数据或者是G输出的伪造数据
- D的输出是其对输入的判断分类
- D的目标是尽可能分别出真实和伪造
- GAN模型的优化过程就是G和D的对抗过程(Generative Adversarial Nets)
- 其中的D(..) 和 G(..) 都使用神经网络模型来拟合。
- 当生成器G所产生的数据的概率分布与真实数据的概率分布相同时,目标函数达到最小值,参数达到最优。
训练过程:
- 训练D:
- 从噪声输入向量Z的分布pz(z)中随机采样m个样本组成一组,输入到G;
- 从真实数据分布pdata(x)中随机采样m个样本组成一组,直接输入到D;
- 计算D的损失函数
- 求解LD对θd的导数,梯度上升法更新D的参数θd
- 反复k次
- 训练G:
- 从pz(z)中随机采样m个样本组成一组,输入到G
- 计算G的损失函数
- 求解LG对θg的导数,梯度下降法更新D的参数θg
- 对于G和D的整个训练迭代N次:每次迭代都是先训练k次判别器D,再训练一次生成器G。
GAN模型的特点
- 优点
- 没有引入近似条件和额外假设(相对于VAE)
- 没有依赖马尔科夫链采样(相对于玻尔兹曼机)
- 训练和推理容易并行化(相对于FVBN)
- 缺点
- 伪数据和真实数据的分布没有交集时, 可能出现梯度消失的情况,目标无法优化
- 超参数敏感,网络的结构设定、学习率、初始化状态等超参数对网络的训练过程影响较大,微量的超参数调整将可能导致网络的训练结果截然不同
- DCGAN 论文作者提出了不使用Pooling 层、多使用Batch Normalization 层、不使用全连接层、生成网络中激活函数应使用 ReLU、最后一层使用tanh激活函数、判别网络激活函数应使用 LeakyLeLU 等一系列经验性的训练技巧。但是这些技巧仅能在一定程度上避免出现训练不稳定的现象,并没有从理论层面解释为什么会出现训练困难、以及如果解决训练不稳定的问题。
- 由于约束少,容易mode collapse,难以收敛
- 生成模型可能倾向于生成真实分布的部分区间中的少量高质量样本,以此来在判别器中获得较高的概率值,而不会学习到全部的真实分布
GAN衍生版本
- CGAN 有条件的GAN
- 引入条件向量y,用于约束生成图像的某种属性
- LAPGAN 拉普拉斯金字塔GAN
- 将图像的拉普拉斯金字塔和GAN相结合
- DCGAN
- https://github.com/carpedm20/DCGAN-tensorflow
- 深度卷积GAN
- D和G都用卷积神经网络
- D中池化层被带步长的卷积层替代
- G和D的卷积层输出结果都经过BN层做归一
- G使用ReLU,D使用Leaky ReLU
- 优化器使用Adam
- infoGAN 互信息GAN
- 使用GAN加上最大化生成的图片和输入编码之间的互信息
- 输入构成:
- 不可压缩的噪声向量z
- 可代表明显语义特征的向量c
- LSGAN 最小二乘GAN
- 基于最小二乘法的目标函数分别优化G和D
- WGAN
- 采样地动距离来定义生成数据和真实数据分布之间的差异
RNN models
- 基本 RNN 单元
输入特点:连续输入序列,将输入x0,x1,…,xt作为从0到t时刻的序列
结构特点:有向环连接,层的输出不仅连接到下一层,还连接到自身。层内的计算不是并行而是串行的。
RNNCell: TensorFlow库中的class RNNCell是所有RNN大类模型的抽象类,实现类需要具有__call__、output_size、state_size、zero_state四个属性。
BasicRNNCell: https://github.com/tensorflow/tensorflow/blob/r1.4/tensorflow/python/ops/rnn_cell_impl.py#L238
- LSTM 单元
标准RNN的升级版:输出包含一个记忆向量,表示综合了过去时刻记忆和当前时刻输入所得的新记忆
BasicLSTMCell: https://github.com/tensorflow/tensorflow/blob/r1.4/tensorflow/python/ops/rnn_cell_impl.py#L361
- GRU 单元
Gated Recurrent Units的LSTM的一个变种。
GRUCell: https://github.com/tensorflow/tensorflow/blob/r1.4/tensorflow/python/ops/rnn_cell_impl.py#L272
- 双向GRU 单元
单元中包含两个隐藏层状态,它在RNN单元的基础上增加了相反方向的隐藏层状态转移。 本质上是两个独立基本RNN单元组合而成
- 外加其他特性的RNN单元
https://github.com/tensorflow/tensorflow/blob/r1.4/tensorflow/python/ops/rnn_cell_impl.py
- DropoutWrapper
- 输入向量、隐藏层状态向量、输出向量对应的神经元分别经过Dropout层,屏蔽部分值
- ResidualWrapper
- 输入可以直接与其经非线性变换后的输出组合在一起的特性
- DeviceWrapper
- 使某个RNN单元运行在指定设备上
- MultiRNNCell
- 堆叠多个RNN
Seq2Seq
Transformer models
位置编码Postional Encoding结构
- 对位置编码(Absolute Position Encoding,APE)
- 相对位置编码(Relative Position Encoding,RPE)
Attention结构
在Encoder-Decoder结构中,Encoder把所有的输入序列都编码成一个统一的语义特征c再解码,因此c中必须包含原始序列中的所有信息,它的长度就成了限制模型性能的瓶颈。
attention它是解决 sequence-to-sequence learning 中的这个限制:要求必须把原序列的全部内容压缩到固定长度的vector。
Attention解决这一限制的方法就是:允许decoder回看原序列的 hidden states,这一状态信息作为加权平均值作为decoder的附加输入。
具体计算c_i的方法有很多,比如:我们用 a_{ij} 衡量Encoder中第j阶段的h_j和解码时第i阶段的相关性,最终Decoder中第i阶段的输入的上下文信息 c_i 就来自于所有 h_j 对 a_{ij} 的加权和。
attention结构变种
- Multi-Head Attention(MHA)
- 将输入序列分割为多个子空间(头),每个头独立学习不同的注意力模式
- Grouped-Query Attention(GQA)
- 将查询头(Query Heads)分组,每组共享同一组键/值头(Key/Value Heads),减少KV Cache规模
- Multi-Query Attention (MQA)
- 每个注意力头共享相同的key和value矩阵,但有不同的query矩阵
- Multi-head Latent Attention (MLA)
- 通过低秩压缩KV Cache,比GQA更省内存且效果相当
- Mixture of Block Attention (MoBA)
- DeepSeek Native Sparse Attention (NSA)
- DeepSeek Sparse Attention (DSA)
Linearized / Approximate Attention
Sparse Attention
仅关注序列中的局部区域或以稀疏方式选择部分位置进行注意力计算。不再计算每个Token与所有其他Token的注意力,而是只计算一个稀疏子集。
Cross Attention与Self Attention的区别:
输入来源: Cross Attention:来自两个不同的序列,一个来自编码器,一个来自解码器 Self Attention:来自编码器的同一序列
实现目标: Cross Attention:解码器序列用作查询(Q),编码器序列提供键(K)和值(V),用于在编码器-解码器两个不同序列之间进行注意力转移。 Self Attention:查询(Q)、键(K)和值(V)均来自编码器同一序列,实现编码器序列内部的注意力计算。
Causal mask
通常情况下,causal mask 是一个二维矩阵,其中对角线以下的元素都为1,表示允许当前位置之前的信息流动,而对角线及以上的元素都为0,表示屏蔽了当前位置之后的信息。在序列生成任务中,这种掩码非常重要,因为它确保了模型按照序列的顺序逐步生成输出,而不会提前使用未来的信息。 Causal Mask 是 Transformer Decoder 架构实现“自回归生成”的基石. Causal Mask具体是如何做到当前位置只关注之前位置的?
attention计算优化
- Flash Attention
- 利用 GPU 高速 SRAM 分块计算,避免 HBM(高带宽内存)频繁读写; 将 softmax、掩码等操作合并到单次内核计算中。
- paged attention
- 将注意力矩阵拆分为”页”,仅加载当前计算所需分块(类似操作系统虚拟内存)
- Radix Attention
- 优先处理与缓存前缀匹配的请求(缓存感知调度)
- Decoding Attention
- CachedAttention (原AttentionStore)
Transformer结构
通过这种自注意力机制层和普通非线性层来实现对输入信号的编码,得到信号的表示。
- 把输入句子拆成词,把每个词转换为词向量,那么输入句子就变成了向量列表。
- 输入向量列表进入第一个编码器,它会把向量列表输入到 Self Attention 层,然后经过 feed-forward neural network (前馈神经网络)层,最后得到输出,传入下一个编码器。
- Self-Attention:
- 对输入句子里的每一个词向量,分别和3个矩阵(WQ, WK, WV)相乘,分别得到3个新向量(Query 向量,Key 向量,Value 向量)
- 一个词向量对应的 Query 向量和其他位置的每个词的 Key 向量的点积得分,再除以Key向量长度的开方,把这些得分的序列求softmax,再与Value向量相乘
- Self-Attention:
- 编码器(Encoder):
- 输入嵌入(Input Embedding)
- 位置编码(Positional Encoding)
- N个编码器层(每层包括以下子层)
- 多头自注意力(Multi-Head Self-Attention)
- 加法 & 归一化(Add & Norm)
- 前馈神经网络(Feed-Forward Neural Network)
- 加法 & 归一化(Add & Norm)
- 解码器(Decoder):
- 输出嵌入(Output Embedding)
- 位置编码(Positional Encoding)
- N个解码器层(每层包括以下子层)
- 多头自注意力(Masked Multi-Head Self-Attention)
- 加法 & 归一化(Add & Norm)
- 多头编码器-解码器注意力(Multi-Head Encoder-Decoder Attention)
- 加法 & 归一化(Add & Norm)
- 前馈神经网络(Feed-Forward Neural Network)
- 加法 & 归一化(Add & Norm)
- 最后的线性层和softmax层输出预测结果。
Transformer门派
- 编码预训练语言模型(Encoder-only Pre-trained Models)
- 解码预训练语言模型(Decoder-only Pre-trained Models)
- 基于编解码架构的预训练语言模型(Encoder-Decoder Pre-trained Models)
BERT
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder是不能获要预测的信息的。模型的主要创新点都在pre-train方法上,即用了Masked LM和Next Sentence Prediction两种方法分别捕捉词语和句子级别的representation。
BERT 模型是最经典的编码预训练语言模型,其通过掩码语言建模和下一句预测任务,对 Transformer 模型的参数进行预训练。
GPT
不再需要对于每个任务采取不同的模型架构,而是用一个取得了优异泛化能力的模型,去针对性地对下游任务进行微调。 GPT开启了”大模型“时代。 -> LLM -> 请见另一篇以LLM专题的Blog.
HSTU
Hierarchical Sequential Transduction Units 结构 用 GPT 的训练方式(预测下一步行为)+ GPT 的架构(Transformer),把整条推荐流水线压缩成一个大模型
TIGER
让每个商品有”语义身份证”,推荐变成”生成下一个身份证”的任务
References
- 图解Transformer-en http://jalammar.github.io/illustrated-transformer/
- 图解Transformer-ch https://mp.weixin.qq.com/s/g6EliR8W1AgpLm8QCcxncw
- The Annotated Transformer https://nlp.seas.harvard.edu/2018/04/03/attention.html
- 从Word Embedding到Bert模型—自然语言处理中的预训练技术发展史 https://zhuanlan.zhihu.com/p/49271699
- 美团如何使用 Transformer 搜索排序 https://tech.meituan.com/2020/04/16/transformer-in-meituan.html
- Nvidia的FasterTransformer是一个开源的高效Transformer实现 https://github.com/NVIDIA/FasterTransformer
- 字节开源的Effective Transformer https://github.com/bytedance/effective_transformer
- Transformer及其attention机制 https://zhuanlan.zhihu.com/p/476585349
- 从Attention到Transformer https://qiankunli.github.io/2023/10/30/from_attention_to_transformer.html
- Transformer的最简洁pytorch实现 https://mp.weixin.qq.com/s/rx7SPYr-sEOz_GOYRfSDOw
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- 深度学习中Attention与全连接层的区别何在?
FNN - 利用FM的结果进行网络初始化
| DCN | DCN介绍 |
NFM - 使用神经网络提升FM二阶部分的特征交叉能力
AFM - 引入了注意力机制的FM模型